Software Development Technologies: The Complete Decision Guide for CTOs and Tech Leads
A structured framework for choosing the right stack, tools, and architecture to accelerate your roadmap and protect your margins.
- Your tech stack is a multi-year business commitment — treat it as a strategic decision, not a technical preference.
- Separating runtime stack layers from development tools gives your team the flexibility to evolve each independently.
- Database and backend choices must be driven by data shape, query patterns, and compliance requirements, not trends.
- CI/CD, observability, and security-by-design are baseline expectations for any production system, not optional upgrades.
- A weighted decision matrix and a focused Proof of Concept replace opinion with evidence when selecting a stack.
- Total Cost of Ownership extends well beyond initial build cost — operations, hiring premiums, and technical debt dominate over time.
Table of Contents
- What are software development technologies?
- Tech stack vs. development tools
- Core layers of a modern software stack
- Frontend technology and user experience
- What defines a robust backend architecture?
- Choosing the right database for your product
- Cloud infrastructure and containerization
- CI/CD pipelines and testing tools
- Observability and production stability
- How security influences your technology choices
- Choosing the right programming language
- Monolith or microservices?
- Total Cost of Ownership (TCO)
- Common mistakes when selecting a tech stack
- A proven process for selecting a tech stack
- How AI is changing the development tools landscape
- How Sentice capabilities map to technology decisions
- Comparing common stack profiles at a glance
- Frequently asked questions
Choosing the right software development technologies is one of the most consequential decisions a CEO, CTO, or Tech Lead will make. The stack you select shapes hiring velocity, time-to-market, scalability ceilings, and the long-term cost of ownership. For today’s scaleups, the challenge isn’t a lack of options — it’s filtering through endless frameworks, databases, and cloud services to assemble a combination that actually fits the product, the team, and the business model.
This guide walks through the layers, the trade-offs, and a proven process to help you make confident, evidence-based choices. It covers end-to-end software development from frontend to infrastructure — the same full-lifecycle perspective that Sentice brings as an embedded boutique tech partner to the startups and scaleups we work with every day.
What are software development technologies?
Software development technologies are the foundational building blocks — languages, frameworks, databases, and tools — required to design, build, deploy, and maintain software across its full lifecycle. They span everything a team touches: programming languages such as Python, Go, Java, or TypeScript; frontend and backend frameworks; relational and non-relational databases; cloud platforms; CI/CD pipelines; testing suites; observability tools; and security tooling.
Together, they define what your product can do today and how easily it can evolve tomorrow. A clear definition matters because it forces alignment: when stakeholders agree on scope, decisions about hiring, vendors, and architecture become measurably easier and less political.
The syntax and structure that define how logic is written and organized — Python, TypeScript, React, Django, Spring Boot, and beyond.
Databases, cloud platforms, caching layers, and message brokers that store, move, and protect your data in production.
CI/CD systems, testing suites, observability platforms, and security scanners that keep quality high and deployments safe.
What is the difference between a tech stack and development tools?
A tech stack refers to the integrated runtime layers that power your product in production: the frontend, backend, database, and cloud infrastructure. Development tools, on the other hand, are the utilities your team uses to write, test, and ship that stack — IDEs, version control, CI/CD pipelines, project management platforms, and testing suites.
The distinction matters in architectural decisions. Swapping a tool (for example, switching CI providers) is usually a contained change. Swapping a stack layer (for example, replacing your primary database) is a multi-quarter migration with real risk to revenue.
| Category | Tech Stack (Runtime) | Development Tools (Workflow) |
|---|---|---|
| Examples | React, Node.js, PostgreSQL, AWS | Git, Jira, Jenkins, Jest |
| Impact of change | High — affects users directly | Lower — affects team workflow |
| Decision horizon | 3–5+ years | 1–2 years |
| Owner | CTO / Architect | Engineering Manager / Lead |
What are the core layers of a modern software stack?
A modern stack is typically composed of four primary layers working in concert. The frontend handles the user interface and client-side logic. The backend runs business logic, APIs, and integrations. The database stores and structures persistent data. The infrastructure layer covers cloud compute, networking, secrets management, and security.
On top of these, cross-cutting concerns like observability, CI/CD, and identity management bind everything together. Treating these as modular layers — rather than a single monolithic decision — gives your team the flexibility to scale or replace components independently as the product matures.
Modular layer thinking is what separates teams that can evolve their stack over time from those that face expensive rewrites. Define clear boundaries between layers from day one, and document the interface contracts between them. This is a practice embedded Sentice engineers apply from the very first sprint.
How does frontend technology impact the user experience?

The frontend is where business value meets the user. Choices here directly affect perceived speed, accessibility, and conversion. Modern frontend stacks are built on HTML, CSS, and JavaScript, with frameworks like React, Vue, or Angular providing structure for component-based development and state management.
Performance considerations such as bundle size, lazy loading, server-side rendering, and caching can make or break engagement metrics. The right frontend choice balances development speed — how fast your team can ship features — with runtime performance — how fast users experience the product — and ensures SEO and accessibility are built in from day one rather than retrofitted.
- Bundle splitting and lazy loading by route
- Server-side or static rendering for first paint
- Image optimization and responsive breakpoints
- Core Web Vitals monitored in CI
- Accessibility audited at component level
- Team’s existing proficiency and hiring pool
- SEO requirements (SSR vs. CSR trade-off)
- Complexity of component state and interactions
- Ecosystem maturity and long-term support
- Integration with your design system or CMS
What defines a robust backend architecture?
A robust backend translates business rules into reliable, secure, and performant services. Languages like Java, Python, Node.js, and Go each bring different strengths around concurrency, ecosystem maturity, and developer productivity. Beyond language choice, robust backends share common traits: clean API contracts, layered architecture that separates domain logic from frameworks, predictable error handling, and clear authentication and authorization boundaries.
Choosing between REST and GraphQL for data exchange
REST is mature, cache-friendly, and widely understood, making it the default for most public APIs. GraphQL shines when clients need flexible querying across complex, related data — such as dashboards or mobile apps with bandwidth constraints. The right choice depends on consumer patterns, not hype. Many teams run both: REST for third-party integrations and GraphQL for internal product clients.
Managing performance with caching layers and message brokers
Caching (Redis, Memcached) and message queues (Kafka, RabbitMQ, SQS) are the workhorses of scalable backends. They absorb traffic spikes, decouple services, and protect databases from overload — turning brittle systems into resilient ones. Introducing these components at the right moment in your product lifecycle, rather than prematurely, keeps operational complexity proportional to actual need.
How should you choose the right database for your product?
Database choice is one of the highest-cost decisions in your stack. Relational databases (PostgreSQL, MySQL) excel at structured data, transactions, and strong consistency — making them ideal for financial, e-commerce, and B2B systems. Non-relational options (MongoDB, DynamoDB, Cassandra) offer flexibility for unstructured data, horizontal scale, and high write throughput.
The decision should be driven by data shape, query patterns, consistency requirements, expected volume, and regulatory constraints — not by what is trending. Many mature products combine both: a relational system of record alongside specialized stores for caching, search, or analytics.
Start with PostgreSQL for almost every new product. Its support for JSON columns, full-text search, and extensions like TimescaleDB means you can defer the decision to add a specialized store until you have real data proving you need it. Premature polyglot persistence adds operational cost before it adds value.
Why is cloud infrastructure and containerization critical today?
Cloud infrastructure provides elastic compute, storage, and networking on demand, while Infrastructure as Code (IaC) tools like Terraform make environments reproducible and auditable. Containerization with Docker, orchestrated by Kubernetes, solves the “it works on my machine” problem by packaging applications with their dependencies for consistent execution across dev, staging, and production.
Together, they enable predictable deployments, faster recovery, and efficient resource use. For teams operating in regulated environments, structured planning aligned with established cloud readiness principles helps ensure that agility doesn’t come at the cost of governance or compliance.
Teams that adopt IaC from the start report significantly faster environment provisioning and a dramatic reduction in configuration drift between environments. When your infrastructure is code, it is reviewable, testable, and version-controlled — the same discipline you apply to your application.
How do CI/CD pipelines and testing tools ensure code quality?
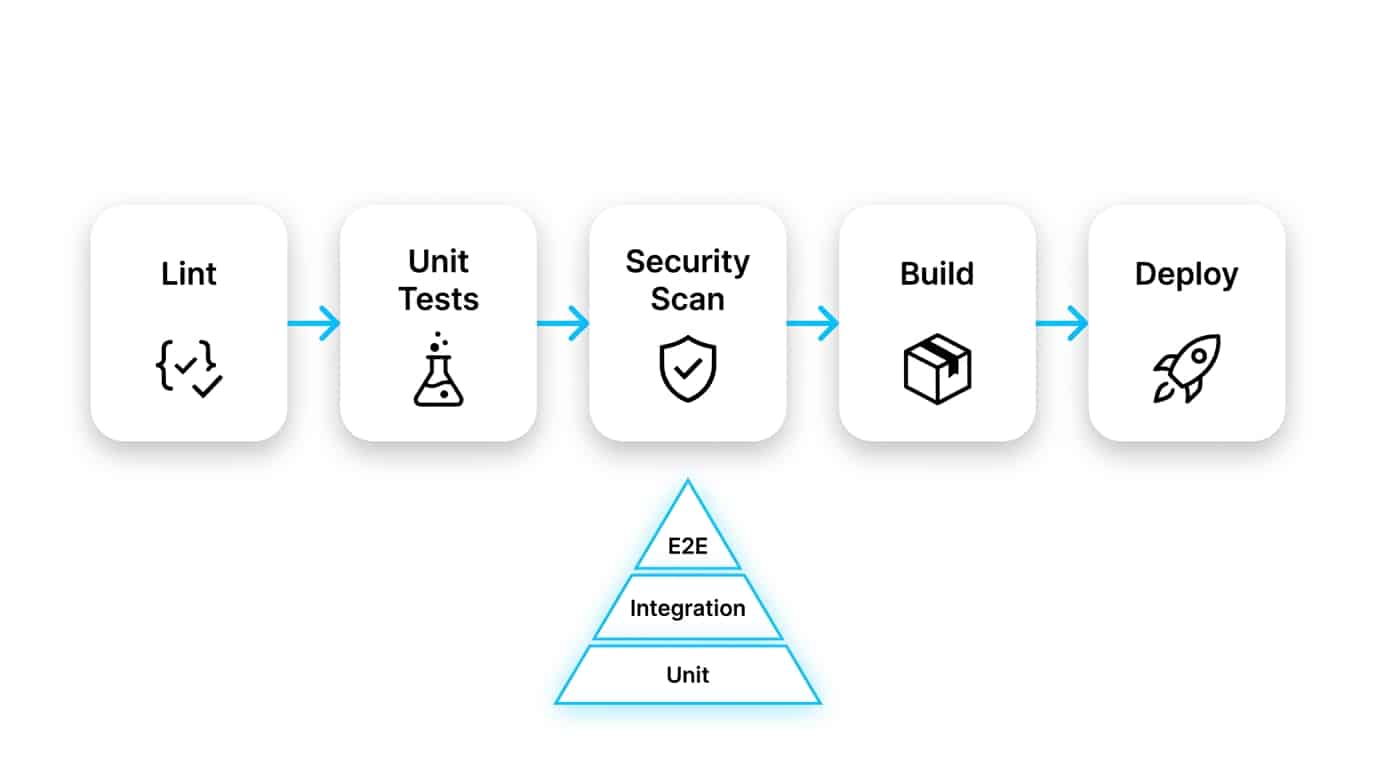
CI/CD is the backbone of continuous delivery. A healthy pipeline runs linting, unit and integration tests, security scans, builds artifacts, and deploys to environments automatically — with safe rollback paths. The result: shorter feedback loops, fewer production incidents, and a team that can ship daily with confidence. Research referenced in NIST guidelines on minimum standards for developer verification reinforces that automated testing, threat modeling, and static analysis are baseline expectations, not nice-to-haves.
The testing pyramid: prioritizing unit, integration, and E2E tests
The testing pyramid keeps quality affordable. A broad base of fast unit tests, a smaller layer of integration tests, and a thin top of end-to-end tests gives you wide coverage without the brittleness or runtime cost of an inverted approach. Teams that invert the pyramid — too many slow E2E tests, too few fast unit tests — pay a compounding tax on every pipeline run, every sprint.
- Linting and static analysis on every PR
- Unit and integration test suites gate merges
- Automated dependency and vulnerability scanning
- Build artifact versioning and provenance
- Rollback path defined before first production deploy
- Environment parity across dev, staging, production
- Feature flags for safe incremental rollout
- Smoke tests run automatically post-deploy
- Deployment frequency tracked as a DORA metric
- On-call runbooks linked to each service deployment
What is observability and how do you monitor for production stability?
Observability is the ability to understand system behavior from the outside in, using three pillars: logs (what happened), metrics (how often and how fast), and traces (the path of a request across services). With dashboards, SLOs, and intelligent alerting, your team can detect anomalies early and identify root causes in minutes rather than hours.
Strong observability is the difference between reactive firefighting and proactive engineering, and it directly protects revenue by reducing mean time to recovery during incidents. Teams with mature observability practices consistently report lower change failure rates and faster incident resolution — two of the four DORA metrics that correlate with high-performing engineering organizations.
How does security influence your technology choices?
Security shapes which components you can use, how you manage secrets, how you authenticate users, and how you handle data at rest and in transit. The “security by design” philosophy means embedding controls from the first commit, not bolting them on before launch. Dependency management, supply chain scanning, and least-privilege identity policies are now table stakes for any product handling user data.
Frameworks like Microsoft’s Security Development Lifecycle (SDL) provide a practical blueprint for integrating security reviews, threat modeling, and automated scanning into every phase of development — a model that maps cleanly to the full-SDLC approach Sentice applies across every engagement.
How do you choose the right programming language for a new project?
Language selection should be driven by four factors: how well the language fits the problem domain, your team’s existing proficiency, the maturity and breadth of its ecosystem, and its ability to meet non-functional requirements such as latency, throughput, and memory footprint.
A language with a vibrant community, strong tooling, and a deep talent pool reduces hiring friction and long-term maintenance cost. Trendy choices may feel exciting in a kickoff meeting, but they often create staffing and stability problems three years in — when the original champions have moved on and the ecosystem has diverged. Choose for the team that will maintain the codebase, not just the team that will build it.
Before committing to any language or framework, search current job postings in your target hiring markets. If senior candidates with the required proficiency are rare in your geography or remote talent pool, the long-term staffing cost may outweigh any technical advantage. Talent availability is a first-class architectural constraint.
Is it better to start with a monolith or microservices?
For most early-stage products, a modular monolith is the right starting point. It maximizes development velocity, simplifies deployment, and avoids the operational tax of distributed systems — network calls, distributed tracing, data consistency challenges, and richer DevOps tooling all add overhead before they add value.
Microservices add genuine value when team size, deployment independence, or specific scaling needs justify the complexity. The path from monolith to services should be deliberate and grounded in real bottlenecks. Teams looking for practical insights on scaling often find that the discipline of clear module boundaries inside a monolith pays off whether or not services are eventually extracted — because those boundaries become the natural seams for future splits.
How do you calculate the Total Cost of Ownership (TCO) for a tech stack?
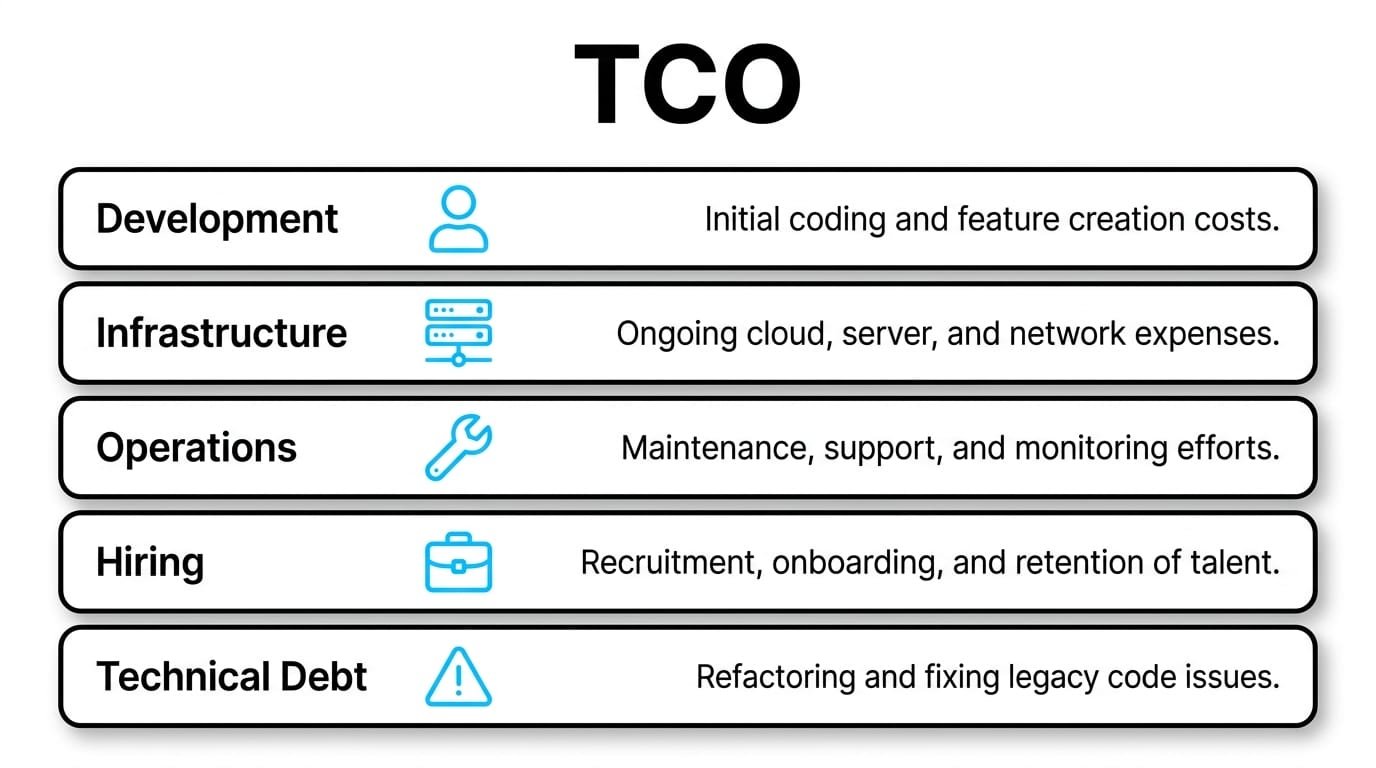
TCO extends far beyond initial development. A realistic model includes infrastructure and licensing, hiring premiums for niche skills, ongoing maintenance, the cost of downtime, the cost of technical debt, and training. Stacks that are cheap to build can be expensive to operate, and vice versa. Mapping these costs upfront prevents painful surprises in year two or three — when the team that chose the stack may no longer be around to explain why.
| Cost Category | What to Include | Often Underestimated? |
|---|---|---|
| Development | Salaries, contractors, onboarding | No |
| Infrastructure | Compute, storage, network, licenses | Sometimes |
| Operations | On-call, monitoring, incident response | Yes |
| Hiring | Talent scarcity premium for niche tech | Yes |
| Technical debt | Refactoring, migrations, rewrites | Yes |
What are common mistakes when selecting a tech stack?
The most expensive mistakes are predictable. “Resume-driven development” — choosing a technology because it looks good on a CV rather than because it fits the problem — leads to over-engineered systems no one can maintain. Premature optimization for scale you don’t yet have wastes months of engineering time. Picking niche technologies without a viable hiring market traps you with the original team as the single point of failure.
Ignoring non-functional requirements until launch produces brittle products that fail under real user load. And building architecture before validating the product creates expensive monuments to assumptions that didn’t survive contact with users. Each of these mistakes has a common root: prioritizing technical opinion over business evidence.
- Resume-driven development — choosing tech for CVs, not fit
- Premature scale optimization before product-market fit
- Niche technology choices with thin hiring markets
- Non-functional requirements treated as post-launch concerns
- Architecture designed before product assumptions are validated
- Ignoring exit strategy and vendor lock-in from day one
What is a proven process for selecting a tech stack?
A disciplined selection process replaces opinion with evidence. It starts with documenting non-functional requirements — throughput, latency, availability, compliance — and locking them in writing before any candidate evaluation begins. Next, define a shortlist of candidate stacks and run a focused Proof of Concept against the riskiest assumptions, not the easiest ones. The POC should expose unknowns, not confirm preferences.
Finally, score candidates with a weighted decision matrix that includes hiring availability, ecosystem maturity, operational cost, and exit strategy. This approach turns stack selection from a debate into a defensible business decision that can be revisited, audited, and improved over time.
Decision matrix: criteria, weights, and scoring
Common criteria include performance fit, team proficiency, hiring market depth, ecosystem maturity, security posture, operational cost, and vendor lock-in risk. Weights should reflect business priorities — if your product operates in a regulated market, security posture and compliance tooling carry more weight than raw performance. If you are in hypergrowth hiring mode, talent pool depth may be the dominant factor. The discipline of making weights explicit is what separates a matrix from a rubber stamp.
How is AI changing the software development tools landscape?
AI-assisted coding, automated test generation, intelligent log analysis, and PR summarization are measurably increasing developer productivity. Studies across engineering organizations consistently show meaningful reductions in time to first working draft for routine code tasks. At the same time, AI raises the bar for code review, architectural oversight, and security scanning — because the volume of generated code increases faster than the capacity to review it carefully.
AI accelerates output but can also accelerate the spread of subtle bugs, outdated API usage, and inconsistent patterns across a codebase. The teams getting the most value treat AI as a force multiplier on top of strong engineering standards — not a replacement for them. Pairing AI tooling with rigorous code review, automated testing, and clear architectural guardrails is the configuration that delivers sustained gains rather than short-term velocity followed by quality regression.
How do Sentice capabilities map to common technology decisions?
Choosing technologies is easier when you have an embedded partner who understands the trade-offs from direct experience. As a boutique tech partner, Sentice works as a culture-aligned extension of your team — not a vendor delivering handoffs. The table below maps typical business needs to how this partnership model supports them in practice.
| Business Need | How a Boutique Partner Helps |
|---|---|
| Accelerating roadmap delivery | Senior, embedded engineers aligned with your existing team and culture |
| Selecting the right stack | Decision frameworks, POCs, and architectural reviews tailored to your product |
| Scaling without losing quality | Established CI/CD, testing, and observability practices applied from day one |
| Managing security and compliance | Security-by-design integrated across the full SDLC |
| Controlling long-term cost | TCO-aware architecture choices and clear exit plans for every layer |
Comparing common stack profiles at a glance
Different products call for different stack profiles. The comparison below is illustrative — your specific requirements will refine it — but it shows how the same components serve different goals and why context always overrides convention.
| Profile | Typical Frontend | Typical Backend | Typical Data | Best For |
|---|---|---|---|---|
| SaaS web app | React / Next.js | Node.js or Python | PostgreSQL + Redis | Fast iteration, B2B |
| Data-heavy platform | React / Vue | Python or Java | PostgreSQL + warehouse | Analytics, reporting |
| Mobile-first product | React Native / native | Go or Node.js | PostgreSQL + cache | Consumer scale |
| High-throughput backend | Light frontend | Go or Java | Mixed SQL/NoSQL | Real-time, fintech |
Frequently asked questions
How long does it take to migrate from one technology to another?
Migrations typically take from one quarter for contained services to several quarters for core platforms. The timeline depends on data volume, integration surface, and how well the original architecture isolated the component being replaced. Teams with clear module boundaries and strong test coverage migrate significantly faster than those without.
Should we choose trendy or mature technologies?
Mature technologies usually win for production systems because of hiring availability, documentation, and community support. Trendy choices can make sense for isolated, well-bounded components where the upside is significant and the blast radius is small. The key is conscious trade-offs, not reflexive conservatism or reflexive novelty-seeking.
How do we measure the scalability of our stack?
Use load testing against realistic traffic patterns, track latency percentiles (P95, P99), and monitor resource saturation under stress. Scalability isn’t a single number — it’s the relationship between cost, performance, and reliability as load grows. Establish baseline measurements before you need them so you can detect degradation early.
Is open source always cheaper than proprietary tools?
Not necessarily. Open source removes licensing fees but shifts cost to integration, support, and operations. The right comparison is total cost of ownership including engineering time, not sticker price. Some proprietary managed services cost more per month but save many times that in avoided operational complexity.
How do we avoid vendor lock-in when choosing cloud providers?
Use abstractions like containers and IaC, prefer open standards where possible, and document a realistic exit plan for each major dependency. Some lock-in is acceptable when the productivity gain is high — the goal is conscious trade-offs, not zero lock-in. Fully portable architectures often sacrifice too much developer experience to be practical.
What is the minimum testing setup for a production system?
At a minimum: unit tests for core logic, integration tests for critical paths, automated security scans in CI, and a small set of end-to-end smoke tests covering the most important user journeys. This baseline prevents the most common categories of production incidents without adding unsustainable pipeline overhead.
When should we invest in dedicated DevOps and SRE roles?
When deployment frequency, environment complexity, or incident volume start consuming meaningful engineering time — usually around the point where you have multiple services in production or strict uptime commitments to customers. Until then, embedding DevOps practices into the engineering team directly is often more effective than creating a separate function.
How does an embedded tech partner differ from a traditional agency?
A traditional agency typically delivers a fixed scope and hands it over. An embedded partner like Sentice integrates into your product organization, participates in planning and architecture, aligns with your culture and ways of working, and shares accountability for outcomes — not just deliverables. The result is faster ramp-up, lower attrition risk, and a team that genuinely extends your internal capability rather than running in parallel to it.
Sentice is a boutique tech partner that builds custom software solutions for startups and scaleups. We embed senior engineers into your product organization as a real extension of your team — culture-aligned, end-to-end, and committed to your roadmap.