Development for Scale-Ups: A Practical Engineering Framework for Growth-Stage Companies
From validated product to reliable platform — the engineering disciplines that separate scale-ups that grow confidently from those that stall.
- Scaling engineering is a strategic discipline distinct from early-stage prototyping — it demands durable architecture, disciplined CI/CD, and security-aware infrastructure from day one.
- Technical bottlenecks — rising rollback rates, long pull-request cycle times, and key-person dependencies — are often misread as headcount problems when they are really maturity problems.
- DORA metrics (deployment frequency, lead time, change failure rate, MTTR) are the most reliable way to measure whether your delivery system is actually improving.
- Investing in platform engineering and standardized onboarding before aggressively hiring prevents new engineers from amplifying chaos rather than throughput.
- A culture-aligned, embedded boutique partner can bridge the gap between growth-stage urgency and enterprise-grade rigor without the overhead of a large vendor rotation cycle.
- Security and compliance built into the delivery pipeline from the start unlocks enterprise sales motions far more reliably than bolting them on pre-audit.
Table of Contents
- What is development for scale-ups?
- Why scaling technology demands a fundamental shift
- Identifying the technical bottleneck before it stalls growth
- How to sustain engineering velocity without sacrificing quality
- Building scalable architecture for a growth stage company
- Infrastructure scale vs. team scale: what comes first?
- Team augmentation versus managed teams
- The role of a Fractional CTO in technical governance
- Streamlining the onboarding process for new developers
- Security and compliance by design
- Establishing a CI/CD culture that supports daily releases
- Integrating QA and test automation at the right layers
- Managing performance under heavy load
- Common mistakes growth stage companies make when scaling engineering
- Balancing roadmap priorities with technical health
- How to measure the success of an expansion support partner
- How to select a technology development partner
- Frequently asked questions
For today’s growth-stage companies, the biggest engineering challenge isn’t writing more code — it’s building a delivery system that holds up under real-world pressure. Once product-market fit is validated, the rules change: customers expect uptime, enterprise buyers demand security audits, and your team is suddenly shipping under conditions the original architecture was never designed to handle. This is the exact moment where development for scale-ups becomes a strategic discipline of its own, distinct from early-stage prototyping and from mature enterprise IT.
In this guide, you’ll find a practical framework for navigating that transition — from architecture and CI/CD to team models, compliance, and how to choose a partner who can deliver consistently as you grow. Sentice works as a boutique tech partner embedded directly into growth-stage product organizations, helping teams build the systems and culture needed to scale delivery without sacrificing quality.
What is development for scale-ups?
Development for scale-ups is the engineering practice of moving a validated product from “it works” to “it works reliably for thousands of paying customers.” It blends durable architecture, disciplined delivery lifecycles, and security-aware infrastructure — not just feature output. At this stage, your team is no longer optimizing for speed of validation; you’re optimizing for predictable, repeatable releases under growing load.
A boutique partner offering end-to-end software development can bridge the gap by embedding senior engineers who understand both growth-stage urgency and enterprise-grade rigor. The goal is to build a system where adding users, customers, and engineers doesn’t multiply chaos — it compounds value. Think of it less as scaling a codebase and more as scaling a delivery organization.
Systems designed around non-functional requirements — latency, availability, cost, and security — that remain maintainable and extensible as load and team size grow.
The end-to-end process from code commit to production deployment, including CI/CD, automated testing, security scanning, and observability instrumentation.
The practice of designing systems to fail safely and recover quickly, replacing heroic on-call firefighting with automated detection, rollback, and restoration.
Why scaling technology demands a fundamental shift
The shortcuts that helped you launch — manual deployments, shared databases, “we’ll fix it later” comments — become liabilities once your customer base, contract size, and team headcount grow. In a startup, technical debt is acceptable currency; in a scale-up, it directly translates into churn, missed SLAs, and lost enterprise deals.
The shift is cultural as much as technical: your team must move from heroic firefighting to engineered resilience, from “ship it” to “ship it safely, observably, and repeatedly.” Scaling technology means investing in foundations that make every future feature cheaper, faster, and safer to deliver. Teams that navigate this transition successfully treat every architectural decision as a long-term commitment, not a short-term workaround.
The moment you sign your first enterprise contract or cross 10,000 active users, your engineering organization faces a fundamentally different set of demands. Uptime SLAs, penetration test requirements, and audit trails are no longer optional — they become table stakes for retaining and growing revenue. The organizations that anticipate this shift and invest in delivery infrastructure ahead of demand consistently outperform those that react to it under pressure.
Identifying the technical bottleneck before it stalls growth
Many growth-stage companies assume they need more developers when, in reality, they need better systems. Common warning signs that the bottleneck is technical — not headcount — include increasing rollback rates, longer pull-request cycle times, deployments that require “all hands on deck,” and a growing reliance on a few senior engineers who hold the system in their heads.
When manual QA becomes the gating factor for releases, or when on-call rotations dominate your senior team’s calendar, you’re not facing a capacity problem. You’re facing a maturity problem in your engineering velocity. Hiring more engineers into a broken system rarely solves it — it typically amplifies the friction instead.
- Deployments require manual coordination across multiple engineers
- No automated rollback capability exists in your pipeline
- Release notes are written from memory rather than from commit logs
- Feature branches live for more than three days on average
- Test coverage is undefined or below 40% on critical paths
- Two or fewer engineers understand the full system end-to-end
- New engineers take more than three weeks to deploy independently
- On-call incidents interrupt planned sprint work weekly
- Architecture decisions are made ad hoc without documented rationale
- Security review is a pre-sales activity, not a continuous practice
How to sustain engineering velocity without sacrificing quality
Sustainable velocity comes from automation and standards, not from working longer hours. The most reliable framework for measuring this is the DORA model, which tracks deployment frequency, lead time for changes, change failure rate, and mean time to restore. Research from Google Cloud on the Four Keys to DevOps performance shows that elite teams ship more often and recover faster precisely because they invest in automation, observability, and trunk-based workflows.
For your team, the takeaway is direct: stop measuring “how busy people are” and start measuring how reliably the system delivers value. Teams that report weekly on DORA metrics consistently close the gap between planned and actual delivery faster than those relying on story-point burn-down charts.
Which metrics actually reflect real engineering velocity?
Story points and tickets closed are vanity metrics. Lead time from commit to production, change failure rate, and mean time to restore tell you whether your delivery system is actually getting faster and safer over time. Pair these with cycle-time analytics from your version control system to identify bottlenecks in code review, testing, or deployment stages. A target benchmark for a high-performing scale-up team is a lead time under one day and a change failure rate below 5% — achievable within two quarters of focused investment in CI/CD and observability.
If you don’t yet have DORA metrics instrumented, start by measuring just two things: how long a pull request sits before it’s reviewed (review lag), and how often a deployment requires a same-day rollback. These two numbers will surface your highest-leverage improvement opportunities faster than any other diagnostic.
Building scalable architecture for a growth stage company
Scalable architecture is rarely about rewriting everything. The “overengineering trap” — jumping prematurely to microservices, Kubernetes, and event-driven systems — often creates more operational pain than it solves. A pragmatic approach is to start with non-functional requirements (latency, availability, cost, security) and evolve modularity inside your existing system.
Domain-driven boundaries, well-defined APIs, asynchronous queues, and strategic caching often deliver more scale per dollar than a full architectural overhaul. Build for the next 12–24 months of growth, not the next decade. Architectural decisions made at this stage have a long half-life — they compound in both directions, so deliberate choices made with senior guidance consistently outperform reactive rewrites made under pressure.
A well-modularized monolith with clearly defined domain boundaries can typically support teams of 20–30 engineers and hundreds of thousands of users before a service extraction strategy becomes necessary. Many scale-ups that migrate to microservices before this threshold report a 30–50% increase in operational overhead without a commensurate improvement in delivery speed — at least in the first 12 months post-migration.
Infrastructure scale vs. team scale: what comes first?
Adding engineers before stabilizing your delivery infrastructure tends to amplify chaos rather than throughput. Without standardized CI/CD, observability, and documentation, every new hire increases merge conflicts, onboarding overhead, and integration friction. The math is unforgiving: a team of 8 engineers with a broken delivery system does not become more productive by growing to 12.
Platform engineering — building internal tooling, golden paths, and self-service infrastructure — is what allows teams to grow without each new squad reinventing deployment, monitoring, and security practices from scratch. Invest in the platform first, then scale the people who use it. The resulting reduction in onboarding time and incident rate consistently more than pays for the platform investment within two to three quarters.
Team augmentation versus managed teams
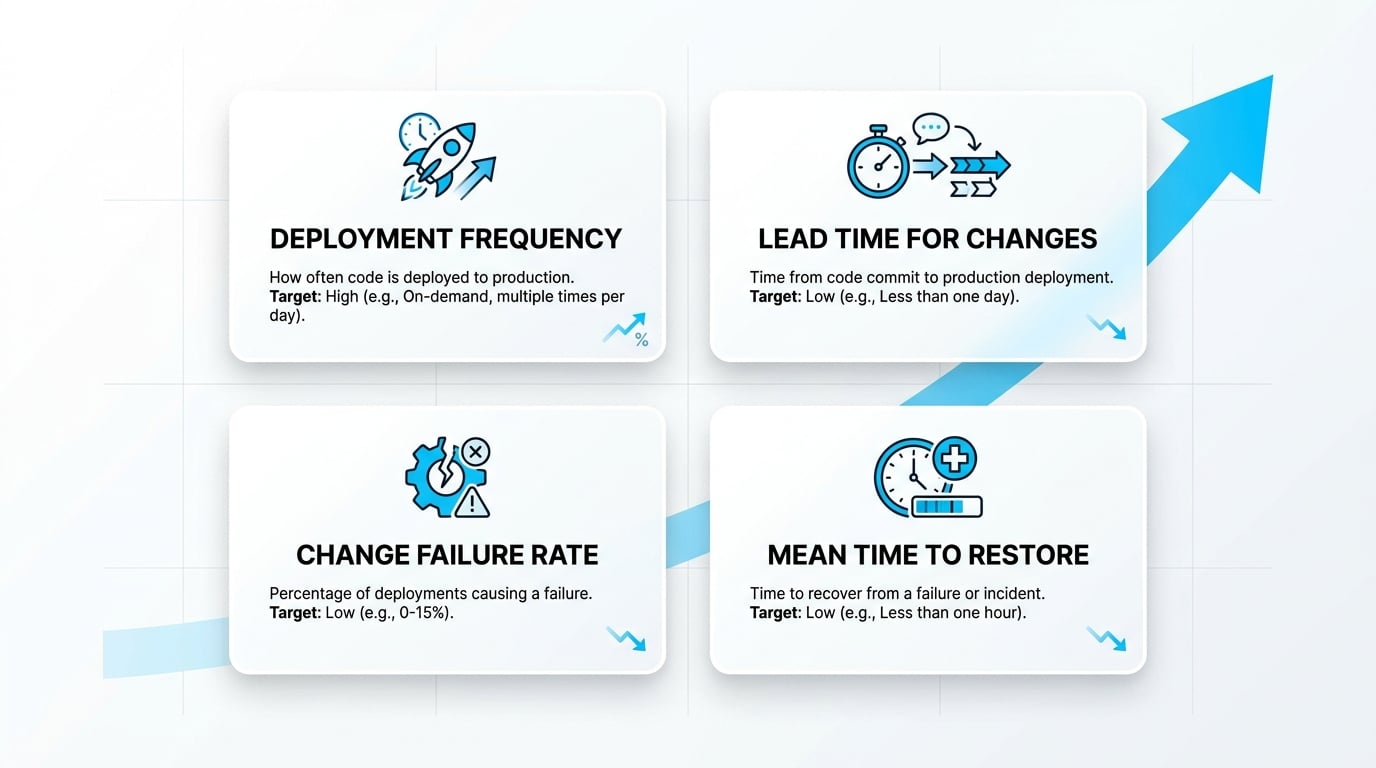
Both models add capacity, but they solve different problems. Choosing the right one depends on your internal leadership maturity and how you want to allocate management overhead. A boutique embedded team in either model should feel like a genuine extension of your team — culture-aligned, aligned to your standards, and invested in your long-term roadmap.
| Dimension | Team Augmentation | Managed Team |
|---|---|---|
| Best when | You have strong internal Tech Leads and PMs | You lack delivery management capacity |
| Management ownership | Internal | External partner |
| Accountability for delivery | Your team | The partner |
| Onboarding speed | Faster (joins existing process) | Slightly longer (sets up own pod) |
| Best output | Extra hands on existing roadmap | End-to-end module or product line |
The role of a Fractional CTO in technical governance
Many growth-stage companies aren’t ready for a full-time CTO at $400K+ but genuinely need senior technical leadership. A Fractional CTO provides strategic governance — architecture decisions, hiring standards, security posture, vendor selection, and roadmap alignment — at a fraction of the full-time cost. This is especially valuable when you have capable developers but no one setting the long-term technical direction or defending platform investments at the executive level.
Trusted advisors in this role help you avoid expensive mistakes that compound over years: premature microservices migrations, underspecified vendor contracts, inadequate access control models, and roadmap commitments that outpace your delivery system’s actual capacity. A part-time senior voice shaping architecture decisions is consistently more valuable than several additional mid-level engineers executing in the wrong direction.
Streamlining the onboarding process for new developers
A great onboarding process gets new engineers — internal or embedded — productive within days, not weeks. The benchmark to aim for is “Day 1 commit, Day 5 production deployment.” That requires deliberate preparation: pre-provisioned access, documented architecture walkthroughs, runbooks, and a curated first task that exercises the full delivery pipeline end-to-end. When this infrastructure is in place, you reduce ramp-up time by 60–70% compared with ad hoc onboarding and dramatically decrease the first-month attrition risk for new hires.
| Onboarding Asset | Purpose | Owner |
|---|---|---|
| Access and SSO setup | Eliminate Day 1 blockers | IT / DevOps |
| Architecture walkthrough | Mental model of the system | Tech Lead |
| Coding standards and PR guide | Consistency across contributors | Engineering Manager |
| Runbooks and on-call docs | Operational readiness | SRE / Platform |
| “Hello-world” delivery task | Validate end-to-end pipeline | Onboarding buddy |
Security and compliance by design
Enterprise customers will ask for SOC 2, ISO 27001, penetration test results, and detailed access control policies long before they sign. Bolting security on after the fact is expensive and slow; building it in from the start is dramatically cheaper and far less disruptive to your delivery cadence. The control families defined in NIST SP 800-53 Rev. 5 — covering access control, audit logging, encryption at rest and in transit, and remote access — give you a battle-tested blueprint that maps cleanly onto SOC 2 trust service criteria.
Implementing SSO, RBAC, audit trails, and secrets management as default infrastructure — rather than pre-sales checklists — is what unlocks your enterprise sales motion and keeps your security posture defensible between annual audits. Teams that treat security as a continuous delivery practice rather than a periodic review consistently achieve audit readiness in half the time.
Establishing a CI/CD culture that supports daily releases
A mature CI/CD pipeline is the backbone of a confident scale-up. It should automate testing, security scanning, build artifacts, and deployments — with rapid rollback as a first-class capability, not an afterthought. Feature flags decouple deployment from release, letting you ship code to production safely and enable it for specific user cohorts only when ready. Canary releases and progressive rollouts further reduce blast radius when something unexpected surfaces in production.
The cultural shift is equally important: small, frequent changes are statistically safer than large, infrequent ones. Teams that ship daily with automated guardrails accumulate confidence over time; teams that batch changes into monthly releases accumulate anxiety. The goal is a delivery system where engineers feel safe to deploy on a Friday afternoon — because the rollback is one command away.
Integrating QA and test automation at the right layers
“Shift-left” testing means catching defects as close to the developer’s keyboard as possible. Relying solely on end-to-end tests is slow, brittle, and expensive at scale. The right test pyramid for a scale-up emphasizes fast unit tests, targeted integration tests, contract tests between services (essential when teams work independently on different modules), and a thin layer of end-to-end tests for critical user journeys only.
Combined with automated regression in your CI pipeline, this approach lets your team release daily without fear of silent regressions reaching customers. Manual QA should shift from being a release gate to being an exploratory and edge-case discipline — valuable, but never the bottleneck. Teams that implement this pyramid typically see change failure rates drop by 40–60% within two quarters.
Managing performance under heavy load

When user volume spikes, intuition fails — measurement wins. Application Performance Monitoring (APM), distributed tracing, and structured logging are the instruments you need before you begin optimizing. Without them, performance work is guesswork dressed up as engineering. Common high-leverage improvements include database indexing, query optimization, read replicas, strategic caching layers, rate limiting, and moving heavy or long-running work to asynchronous queues.
Measure first, optimize second, and verify every change with load tests that mirror realistic production traffic patterns — not synthetic benchmarks. The teams that manage load events best are those that have practiced them through game days and chaos engineering exercises before a real spike arrives. Preparation converts performance crises into routine operational events.
Before committing engineering time to any performance optimization, ensure you have three things in place: distributed tracing across all service boundaries, structured logs with consistent correlation IDs, and real user monitoring (RUM) on your frontend. Without these, you risk optimizing the wrong layer — improving database query time by 30% while the actual bottleneck is a blocking synchronous call to a third-party API.
Common mistakes growth stage companies make when scaling engineering
The same patterns repeat across scale-ups — and most are avoidable with early awareness. Hiring aggressively before fixing process. Migrating to microservices because “everyone does it.” Ignoring observability until production breaks in front of a major customer. Treating security as a pre-sales checklist rather than a daily practice. Outsourcing without defining clear ownership, escalation paths, and delivery accountability.
Each of these mistakes is expensive to reverse, which is why early architectural and operational decisions deserve disproportionate attention from your most senior people — not just your most available ones. The cost of a poor architectural decision compounds over 18–24 months; the cost of getting it right up front is typically a single sprint of focused senior engineering time.
Balancing roadmap priorities with technical health
One of the hardest disciplines for a scale-up is protecting time for platform work, reliability, and technical debt remediation against constant pressure for new features. A practical model is to allocate engineering capacity quarterly across four explicit buckets: Growth Features, Platform and Infrastructure, Reliability and Security, and Technical Debt remediation. Making this allocation visible — and defending it at the executive level — is what prevents the slow erosion of delivery velocity that eventually forces a painful “stop the world” stabilization sprint.
A commonly effective starting allocation is 60% growth features, 20% platform and reliability, and 20% technical debt — adjusted based on your DORA metrics trend. For deeper guidance on scaling teams without compromising quality, see our perspective on scaling up quickly as a boutique, embedded team approach.
How to measure the success of an expansion support partner
Hours billed is the wrong metric. The right metrics are objective and outcome-based: lead time for changes, deployment frequency, change failure rate, MTTR, defect escape rate, and roadmap commitments delivered on time and within scope. These numbers tell you whether your partner is genuinely moving the delivery system forward or simply maintaining the status quo at cost.
Add qualitative signals — documentation quality, communication cadence, proactive risk surfacing, and how well the partner’s engineers integrate with your team’s culture — and you have a balanced scorecard. A partner worth retaining will welcome this transparency and bring their own reporting to the conversation.
| Business Need | How Sentice Supports It |
|---|---|
| Scaling delivery without losing quality | Embedded senior engineers aligned with your standards and processes |
| Filling technical leadership gaps | Fractional CTO and senior architects for governance and roadmap alignment |
| Preparing for enterprise customers | Security-by-design practices and audit-ready documentation built into delivery |
| Accelerating onboarding of new capacity | Boutique pods that integrate end-to-end into your SDLC within days |
| Reducing technical debt while shipping | Balanced sprint planning across features, platform, and reliability buckets |
How to select a technology development partner
The cheapest hourly rate is rarely the lowest total cost. What matters is proven delivery: case studies in your stage and domain, a documented onboarding process, transparent estimation methodology, clear escalation paths, and a track record of remediating technical debt rather than adding to it. Ask for references from clients who have been with the partner for more than 18 months — those relationships reveal whether the partner can genuinely grow with you as your needs evolve.
A boutique partner aligned with your engineering culture will consistently outperform a large vendor whose senior talent rotates off your account after kickoff. The difference is personal accountability: when the people who designed your architecture are the same people maintaining it six months later, quality compounds rather than erodes. This is the foundation of how Sentice operates — start small, grow fast, and remain your trusted, embedded partner throughout the journey.
Frequently asked questions
What is the difference between product development and “scaling”?
Product development focuses on building and validating features; scaling focuses on making those features reliable, performant, and secure for a much larger customer base. The skills, architecture, and processes required are meaningfully different. A team optimized for rapid experimentation will typically need to restructure its delivery model before it can support enterprise SLAs and high-volume load reliably.
When is the right time to move to microservices?
When your monolith’s deployment cadence, team coordination overhead, or scaling costs become demonstrable bottlenecks — not before. Most scale-ups benefit more from a well-modularized monolith with clear domain boundaries than from a premature microservices migration. The rule of thumb: extract a service when a bounded domain needs to scale or deploy independently, not because of a technology trend.
How do we calculate total cost of ownership for scaling product development?
Include not just engineer salaries or partner fees, but also infrastructure, tooling licenses, security audits, on-call burden, opportunity cost of delayed features, and the direct cost of production incidents. TCO is what reveals whether a “cheap” option is actually expensive over an 18-month horizon. A partner charging 20% more but delivering 40% fewer incidents and faster time-to-market is measurably cheaper on a TCO basis.
What documentation is required to ensure knowledge transfer with an external team?
At minimum: architecture diagrams, domain models, API contracts, runbooks for common operational tasks, on-call playbooks, and an updated README per service or module. Living documentation maintained in the repository alongside the code consistently outperforms static documents in a wiki that go stale within weeks of a major change. A good partner will contribute to this documentation as part of standard delivery practice.
How do we maintain compliance while iterating daily?
By embedding controls into the pipeline: automated security scans on every pull request, policy-as-code for infrastructure provisioning, audit-ready structured logging, and access reviews triggered by your CI/CD system rather than scheduled manually. When compliance is a byproduct of delivery rather than a separate workstream, it scales with your release cadence instead of blocking it.
How long does it take to see velocity improvements after process changes?
Teams typically see measurable improvements in lead time and change failure rate within 6–12 weeks of investing in CI/CD automation, observability instrumentation, and onboarding standards — provided leadership protects the time required to implement them without diverting engineers back to feature work mid-cycle. The first visible signal is usually a drop in rollback frequency and a reduction in review-to-merge lag time.
Is technical debt remediation compatible with a fast feature roadmap?
Yes — when managed explicitly. The key is making the debt allocation visible in sprint planning rather than treating it as invisible overhead. Teams that dedicate a consistent 15–20% of capacity to debt remediation and platform work typically see their feature delivery speed increase over two to three quarters, because the underlying system becomes progressively easier to change. Teams that defer all debt until a “refactor sprint” rarely find that sprint arrives on schedule.
How should we evaluate whether an embedded partner is truly culture-aligned?
Ask the partner to describe how they handled a disagreement with a client’s technical direction in a past engagement. A culture-aligned partner will have a concrete example of raising a concern proactively, explaining their reasoning, and reaching a considered decision collaboratively — rather than silently complying or escalating adversarially. Also ask how they handle knowledge transfer: a partner invested in your long-term success will prioritize documentation and internal capability-building, not dependency.
Sentice is a boutique tech partner that builds custom software solutions for startups and scaleups. We embed senior engineers into your product organization as a real extension of your team — culture-aligned, end-to-end, and committed to your roadmap.