DevOps Services: The Complete Guide for Startups and Scaleups
How professional DevOps services close the gap between writing code and shipping it reliably — turning engineering velocity into measurable business outcomes.
- Professional DevOps services reshape how your team builds, ships, and scales software — not just automate scripts.
- Every engagement should produce client-owned deliverables: IaC repos, CI/CD pipelines, dashboards, and Runbooks.
- Outsourcing DevOps closes the performance gap faster than internal hiring, especially under tight roadmap pressure.
- DORA metrics — deployment frequency, lead time, change failure rate, MTTR — are the industry standard for measuring success.
- DevSecOps, FinOps, and observability are not optional add-ons; they are foundational pillars of a mature delivery platform.
- Kubernetes is not always the right choice — match the tool to your team’s operational maturity and actual scaling needs.
Table of Contents
- Understanding DevOps Services and Their Strategic Fit
- Core Deliverables of Professional DevOps Services
- DevOps Consulting vs. Managed DevOps Services
- Why Outsourcing DevOps Often Beats Hiring Internally
- Pricing Structures in DevOps Consulting
- The Lifecycle of a DevOps Transformation Project
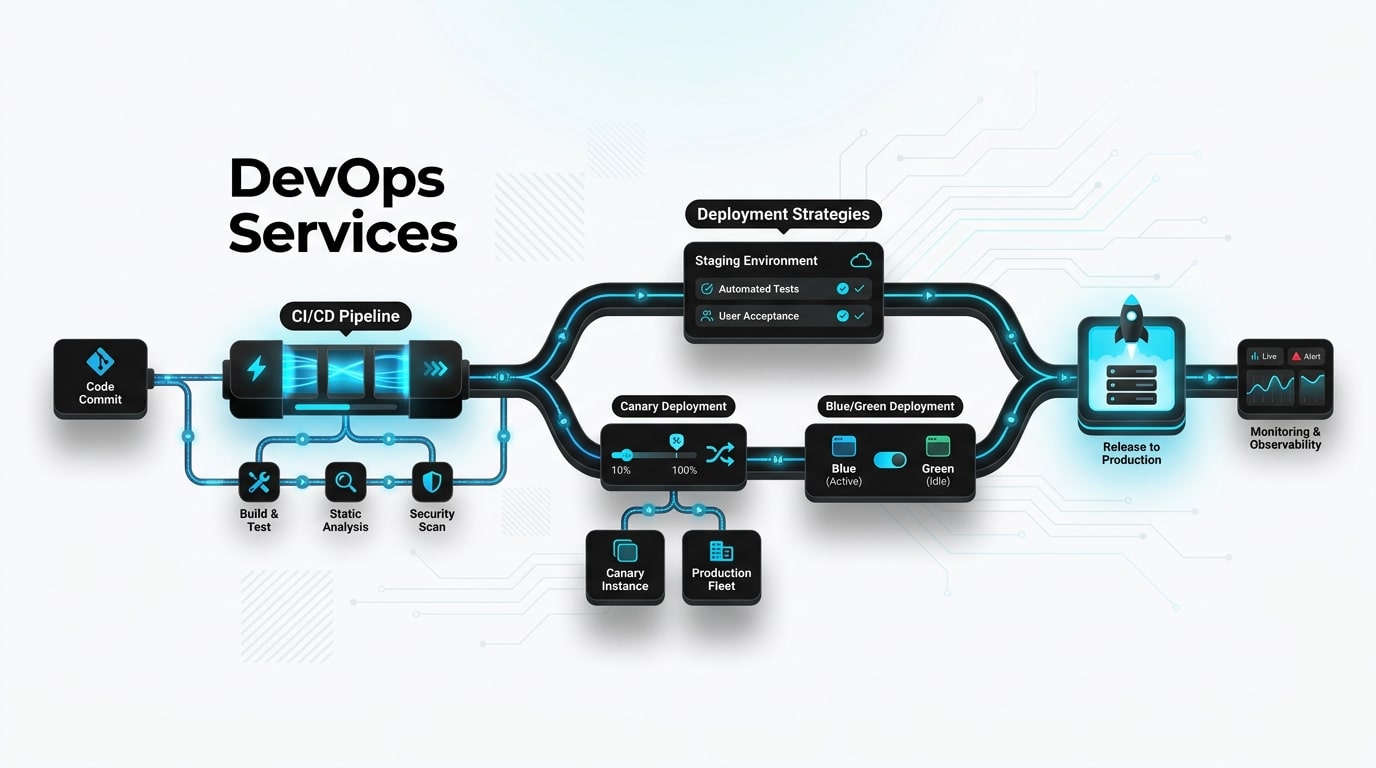
- Enhancing CI/CD Pipelines for Business Velocity
- Infrastructure as Code as a Foundational Pillar
- Integrating DevSecOps Without Blocking Development
- Improving Observability and System Reliability
- Optimizing Cloud Costs with FinOps
- When Is Kubernetes Actually the Right Choice?
- Migration Strategies to Modern Cloud Infrastructure
- Differentiating SRE from DevOps Services
- Comparison: Common DevOps Engagement Scenarios
- Common Mistakes Companies Make with DevOps Initiatives
- Critical Checklist for Selecting a DevOps Partner
- Frequently Asked Questions
For today’s startups and scaleups, the gap between writing great code and shipping it reliably to production has become the single biggest bottleneck to growth. Engineering leaders feel the pressure from every direction: faster release cycles, tighter security demands, rising cloud bills, and a market that punishes downtime. This is where professional DevOps services move from a “nice to have” to a strategic lever. Done right, they don’t just automate scripts — they reshape how your team builds, ships, and scales software.
In this guide, we walk through what modern DevOps services actually include, how to evaluate a partner, and how to turn engineering velocity into measurable business outcomes. Whether you’re exploring your first CI/CD pipeline or planning a full platform transformation, Sentice brings the cross-industry patterns and embedded expertise to help you build a delivery system that scales with your business.
Understanding DevOps Services and Their Strategic Fit
DevOps services act as the connective tissue between software development and IT operations. Their purpose is straightforward: deliver software faster, with fewer defects, and with stronger security guarantees. In practice, this means automating repetitive work, codifying cloud architecture, and standardizing how releases reach production. For scaleups, the strategic value is clear — you stop firefighting and start shipping with predictability.
At Sentice, we approach DevOps as a technical partnership rather than a transaction, aligning engineering practices with the business outcomes your leadership team actually cares about: time-to-market, reliability, and cost control. Our full-stack development approach ensures DevOps is woven into the product lifecycle from day one, not bolted on as an afterthought.
The measurable speed at which your team ships validated features to production — directly tied to deployment frequency and lead time for changes.
The ability to maintain agreed service levels under real production conditions, measured through SLOs, error budgets, and mean time to recovery.
Every artifact produced — IaC, pipelines, dashboards, Runbooks — belongs to your organization, not your partner. Full knowledge transfer is non-negotiable.
Core Deliverables of Professional DevOps Services
A serious DevOps engagement is defined by tangible artifacts, not vague promises. You should expect concrete outputs: an Infrastructure as Code (IaC) repository, a working CI/CD pipeline, hardened security baselines, observability dashboards, and operational Runbooks. These deliverables are the difference between “we improved DevOps” and “here is exactly what changed, and how to maintain it.” Critically, every one of these assets must remain under your ownership. A partner who keeps the keys to your infrastructure is creating dependency, not value.
At project completion, your team should hold the IaC templates, pipeline configurations, dashboards, documentation, and all access credentials. A partner who can’t hand these over cleanly hasn’t built you an asset — they’ve built themselves leverage.
Ownership and Knowledge Transfer Requirements
Knowledge transfer sessions, recorded walkthroughs, and clear Runbooks are non-negotiable. At project completion, your team should be able to operate, extend, and recover every system without calling the partner. This is the foundation of avoiding vendor lock-in — and it’s a principle we build into every engagement at Sentice. We treat handover as a delivery milestone, not an afterthought.
DevOps Consulting vs. Managed DevOps Services
These two models look similar but solve different problems. Consulting focuses on improving processes, tooling, and internal capabilities — your team executes, the partner guides. Managed services include ongoing operational responsibility: monitoring, on-call coverage, incident response, and SLA-backed uptime. Choosing the wrong model leads to either underutilized advisors or an over-reliant operations function.
- Process and tooling improvement
- Internal capability building
- Architecture reviews and roadmaps
- Your team executes; partner guides
- Ideal for startups with strong internal staff
- Ongoing operational responsibility
- 24/7 monitoring and on-call coverage
- Incident response and SLA-backed uptime
- Partner executes alongside your team
- Ideal for scaleups with high release cadence
Selecting the Right Engagement Model for Your Stage
Early-stage startups with a strong internal team often benefit most from consulting bursts that establish standards. Scaleups facing 24/7 production demands, regulatory scrutiny, or rapid release cadences typically need a managed component. Evaluate staff maturity, release frequency, and compliance requirements before committing to a model. A hybrid approach — consulting to build the foundation, managed services to sustain it — often delivers the best long-term outcome.
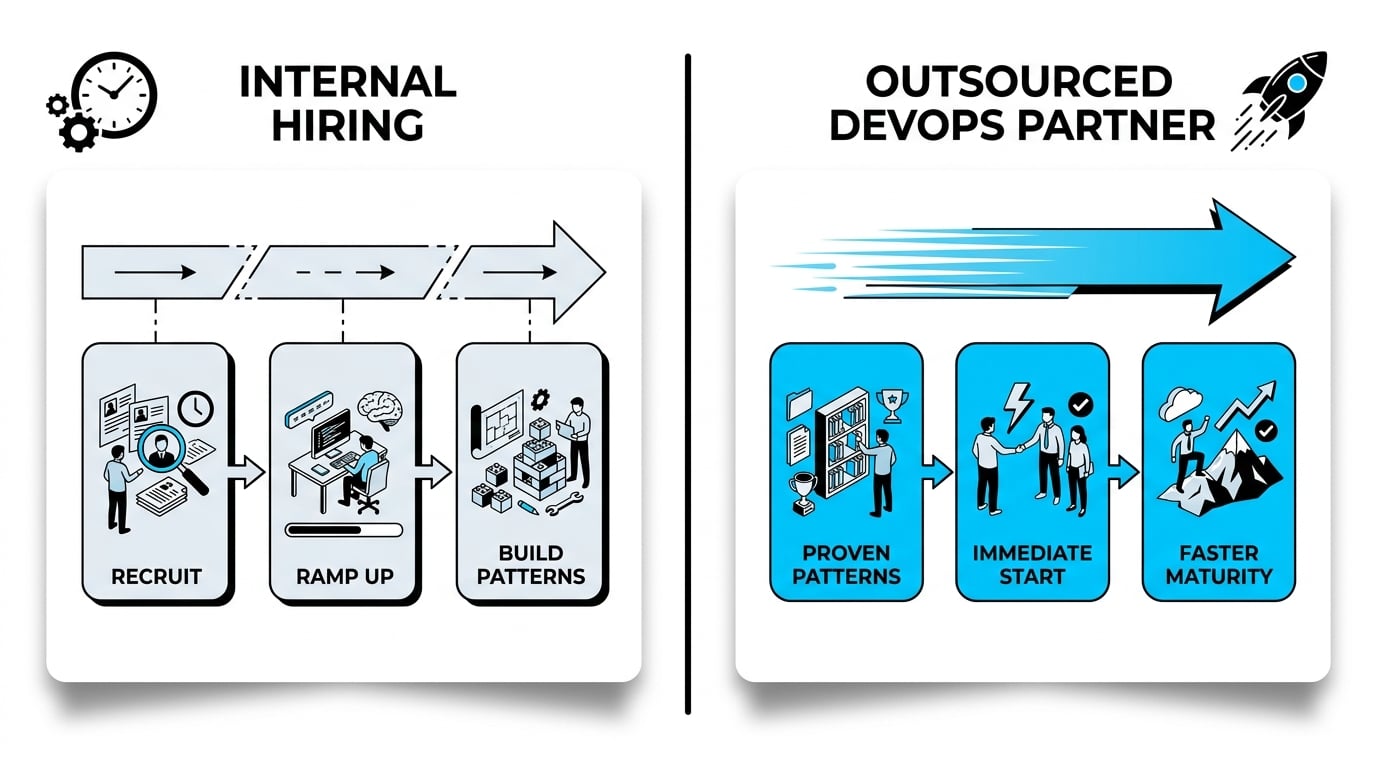
Why Outsourcing DevOps Often Beats Hiring Internally
Hiring a senior DevOps engineer takes months; building a balanced platform team takes years. Meanwhile, your roadmap waits. Outsourcing closes what we call the “performance gap” — the distance between wanting automation and actually implementing it consistently. A specialized partner brings patterns already proven across dozens of environments, accelerating your time to maturity.
This is especially valuable when scaling up tech teams under tight deadlines, where every week of delay translates directly into missed market opportunities. An embedded partner doesn’t need onboarding time to understand DevOps — they arrive with it and adapt it to your context.
Many of the most effective engagements begin with a focused two-week sprint to establish CI/CD foundations. That early win builds internal confidence, surfaces real constraints, and justifies the investment for the broader transformation.
Pricing Structures in DevOps Consulting
DevOps pricing isn’t arbitrary — it reflects scope, complexity, and risk. The main cost drivers are the number of environments, cloud architecture complexity, existing technical debt, compliance requirements, and the level of operational coverage needed. Understanding the pricing model upfront prevents surprises and aligns expectations between engineering and finance teams.
| Model | Best For | Typical Engagement |
|---|---|---|
| Project-based | Defined scope (e.g., CI/CD setup, cloud migration) | Fixed deliverables, 1–4 months |
| Retainer | Continuous improvement and operational support | Monthly hours, ongoing |
| Milestone-based | Transformation programs with phased outcomes | Payment tied to verified deliverables |
Milestone-based pricing is increasingly preferred by engineering leaders because it ties vendor payment directly to verified outcomes — not time spent. It aligns your partner’s incentives with your delivery goals rather than their billable hours.
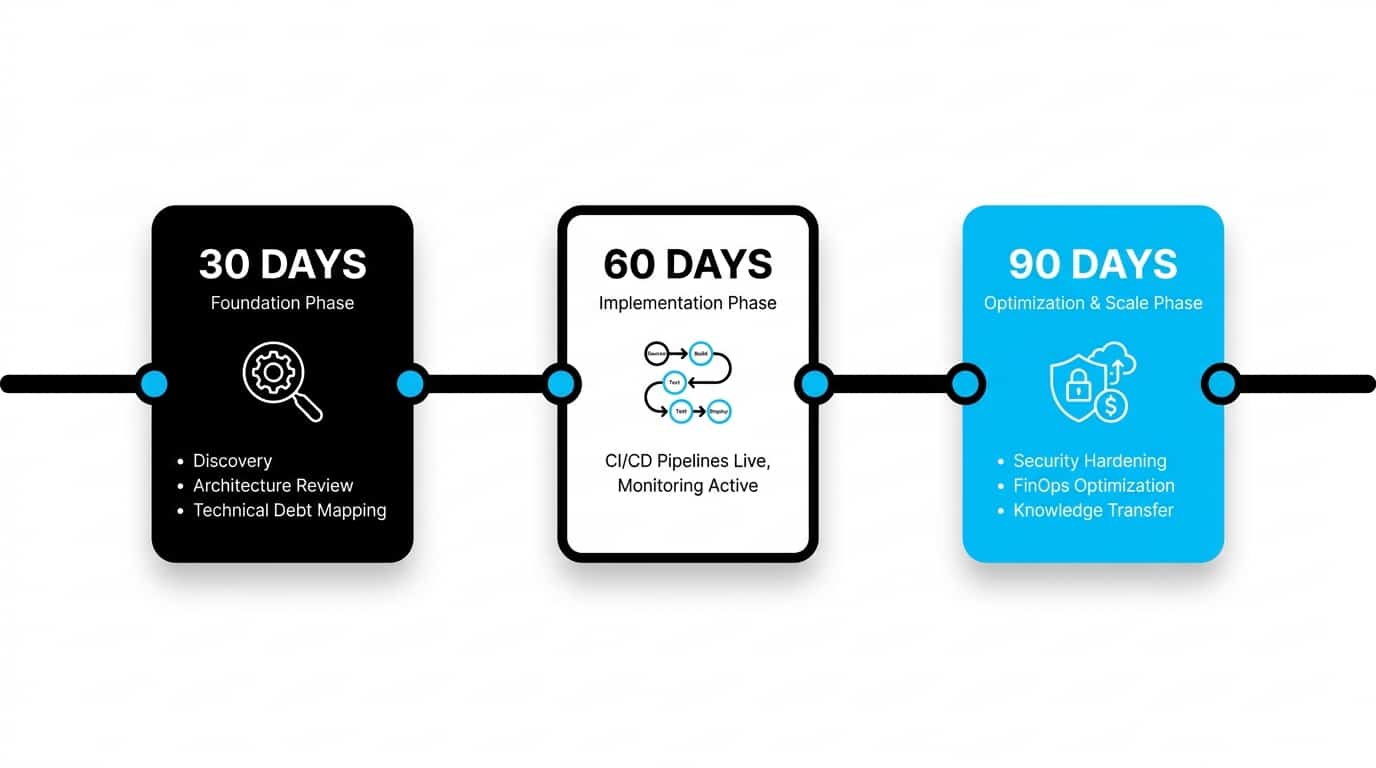
The Lifecycle of a DevOps Transformation Project
A well-run DevOps engagement follows a clear arc: audit existing systems, build a roadmap, secure quick wins, and then implement long-term standards. Skipping the audit phase is the most common — and most expensive — mistake we see. Without baseline measurement, you can’t prove improvement, and you risk rebuilding what already exists rather than addressing what actually needs to change.
Execution Roadmap: 30 / 60 / 90 Days
In the first 30 days, the focus is discovery: architecture review, pipeline inventory, and mapping technical debt. By day 60, foundational CI/CD pipelines and monitoring should be live, delivering the first measurable improvement in deployment frequency. By day 90, the focus shifts to security hardening, FinOps cost optimization, and structured knowledge transfer to your internal team. This cadence balances quick wins with sustainable, lasting change.
Enhancing CI/CD Pipelines for Business Velocity
CI/CD is the engine of modern software delivery. A mature pipeline automates testing, builds, security scans, and deployments — turning hours of manual work into minutes of verified automation. The business outcome is direct: faster releases, fewer rollbacks, and developers focused on features instead of fire drills.
Modern pipelines must also account for software supply chain security. NIST SP 800-204D provides authoritative guidance on integrating security controls directly into CI/CD workflows without slowing delivery — shifting protection left so vulnerabilities are caught at build time rather than in production.
- Automated unit and integration tests
- Static code analysis and linting
- Dependency vulnerability scanning
- Container image security checks
- Gated promotion between environments
- Higher deployment frequency
- Reduced change failure rate
- Lower mean time to recovery
- Developers reclaim time for features
- Auditable release history on demand
Infrastructure as Code as a Foundational Pillar
IaC transforms infrastructure from a manual, error-prone process into a versioned, reviewable codebase. Every environment becomes reproducible, every change auditable, and every rollback predictable. Configuration drift — that quiet killer of staging-versus-production parity — disappears when infrastructure is defined declaratively.
IaC is also the prerequisite for genuine disaster recovery. If you can’t rebuild your environment from code in under an hour, you don’t have a recovery plan — you have hope. Treating infrastructure as software, with the same review and testing discipline, is one of the highest-leverage investments a platform team can make.
Every manual change to a production environment that isn’t reflected in the IaC repository is technical debt accumulating silently. Review your IaC repository against your live environments quarterly, and treat any divergence as a P1 issue.
Integrating DevSecOps Without Blocking Development
Security and speed are often framed as opposites. They aren’t. DevSecOps embeds security checks directly into the pipeline through dependency scanning, container image analysis, secrets detection, and policy-as-code. The goal is “shift-left” — catching issues when they’re cheap to fix, not after deployment when remediation costs are an order of magnitude higher.
Security Essentials for Every Production Pipeline
At minimum, every production pipeline should enforce centralized secrets management, least-privilege IAM policies, automated vulnerability scanning, and immutable audit logs. These four controls eliminate the majority of common breach vectors without adding meaningful friction for developers. The key is automation: security checks that run in the pipeline are invisible to developers working at pace and only surface when action is genuinely required.
Improving Observability and System Reliability
Observability is more than monitoring — it’s the ability to ask new questions about your system without deploying new code. Logs, metrics, and traces, unified in coherent dashboards with alerts tied to business impact, dramatically reduce Mean Time To Repair (MTTR). The difference between a 3-minute recovery and a 3-hour recovery usually comes down to whether your team had the right signals in front of them when the incident started.
Define SLOs and SLIs per service, alert on user-facing symptoms rather than internal noise, and maintain Runbooks that turn 3 AM incidents into routine procedures. Observability is also the foundation of any honest conversation with your leadership team about reliability — if you can’t measure it, you can’t improve it or commit to it.
Start with a single user-facing SLO per critical service — availability or latency at the 99th percentile. Once your team is comfortable responding to error-budget burn alerts, layer in additional indicators. Complexity added too early creates alert fatigue, not reliability.
Optimizing Cloud Costs with FinOps
Cloud bills rarely shrink on their own. FinOps treats cost as a continuous engineering discipline: tag every resource, right-size instances based on real usage, automate shutdowns of non-production environments, and set budgets per team or product. Without visibility, engineers make infrastructure decisions without understanding their cost implications — and the bill reflects that.
The discipline is gaining formal recognition globally, including in government training programs such as the FinOps cloud economics curriculum from Israel’s Ministry of Finance. This signals that FinOps is now a baseline organizational competency rather than an optional optimization — especially relevant for scaleups managing multi-cloud environments under budget scrutiny.
When Is Kubernetes Actually the Right Choice?
Kubernetes has become almost synonymous with modern DevOps, but it isn’t always the right answer. It excels when you have multiple services with independent scaling needs, real traffic variability, multi-cloud portability requirements, or complex deployment topologies. The operational overhead is real and the learning curve is steep — your team will spend meaningful time on cluster management before they spend time on product features.
For an early-stage product with two services and modest traffic, managed container platforms or even traditional VMs may deliver more value with far less operational overhead. The honest test is whether your team has the maturity to operate Kubernetes in production — not whether it looks good on the architecture diagram. Start with what your team can maintain confidently, and migrate when the operational complexity genuinely justifies it.
Migration Strategies to Modern Cloud Infrastructure
Zero-downtime migration isn’t magic — it’s discipline. Blue-green deployments run old and new environments in parallel, switching traffic only after verification. Canary releases route a small percentage of users to the new version, expanding gradually as metrics confirm health. Feature flags decouple deployment from release, letting you ship code dark and activate it on demand — a particularly powerful pattern for high-stakes changes.
Combined with thorough load testing and a documented rollback plan, these techniques make migrations boring — which is exactly what you want. A migration that generates no incidents and no late nights is a well-executed migration. The goal is never excitement; it’s confidence.
Teams that use feature flags report significantly higher deployment frequency because they decouple the risk of releasing from the risk of activating. You can ship to production daily and activate new features only when the business is ready — separating technical delivery from product launch entirely.
Differentiating SRE from DevOps Services
DevOps and SRE overlap, but they aren’t identical. DevOps is a broad set of practices and tools that accelerate delivery. Site Reliability Engineering is a specific operational model — pioneered at Google — that applies software engineering principles to operations, with strict focus on SLOs, error budgets, and reliability as a product feature.
In practice, mature organizations blend both: DevOps for delivery velocity, SRE for reliability discipline. Error budgets, in particular, are a powerful tool — they give your team a concrete, shared answer to the question “how much risk can we afford to take this sprint?” and prevent the false dichotomy of “move fast” versus “stay stable.”
Comparison: Common DevOps Engagement Scenarios

| Business Need | How a DevOps Partner Helps | Typical Outcome |
|---|---|---|
| Slow, error-prone releases | CI/CD pipeline with automated tests and gated promotions | Daily deployments, fewer rollbacks |
| Rising cloud bills | FinOps audit, tagging, autoscaling, right-sizing | 20–40% cost reduction |
| Frequent production incidents | Observability stack, SLOs, on-call playbooks | Lower MTTR, calmer nights |
| Compliance and audit pressure | DevSecOps automation and policy-as-code | Audit-ready evidence on demand |
| Scaling engineering team | Self-service platforms and golden paths | Faster onboarding, less duplicated work |
Common Mistakes Companies Make with DevOps Initiatives
The most expensive DevOps mistakes aren’t technical — they’re strategic. Buying tools before defining outcomes leads to expensive shelfware. Measuring activity (number of deployments) instead of impact (lead time, change failure rate) creates the illusion of progress. Concentrating knowledge in one “DevOps hero” creates a single point of failure — and a single resignation event that sets your platform back by months.
Treating DevOps as a one-time project rather than an ongoing capability guarantees regression within months. Teams that “complete DevOps” and stop investing typically see deployment frequency drop and incident rates climb within a quarter. The fix isn’t more tools — it’s clearer outcomes, shared ownership across the engineering organization, and continuous measurement using the DORA metrics as your compass.
Critical Checklist for Selecting a DevOps Partner
The right questions filter out the wrong partners quickly. Ask: Who owns the code and infrastructure at the end of the engagement? What does the handover process look like? How do you define and measure success? What is your incident response SLA? How do you manage secrets and access? A confident partner answers these directly and with documented examples from previous engagements.
- Clear handover and exit plan from day one
- Defines success in DORA metrics, not activity
- Open-source or client-owned tooling
- Documented knowledge transfer process
- References from similar-stage companies
- Proprietary “black box” tooling
- Refuses to commit to documentation standards
- Can’t articulate a clear exit plan
- Insists on owning the cloud account or IaC repo
- Promises outcomes without describing the process
Your infrastructure should always be yours. A partner who can’t transfer full ownership cleanly at project end hasn’t delivered an asset — they’ve created leverage over your team. Walk away from that arrangement regardless of how compelling the initial pitch sounds.
Frequently Asked Questions
What is included in DevOps services?
Typically: CI/CD pipeline setup, Infrastructure as Code, cloud architecture design, security automation (DevSecOps), monitoring and observability, FinOps practices, and knowledge transfer through documentation and Runbooks. Scope varies by engagement model — consulting engagements tend to focus on tooling and capability building, while managed services include ongoing operational responsibility such as on-call coverage and SLA-backed uptime.
How do you measure DevOps success?
The industry standard is the DORA metrics: deployment frequency, lead time for changes, change failure rate, and mean time to recovery. These four indicators are strongly correlated with both organizational performance and software quality. Combine them with business KPIs like time-to-market and cost per deployment for a complete picture that resonates with both engineering and executive stakeholders.
How does FinOps reduce cloud spending?
FinOps reduces costs through four levers: visibility (tagging every resource so costs are attributable to teams and products), right-sizing (matching instance types to actual usage rather than worst-case estimates), automation (shutting down idle non-production environments outside business hours), and accountability (setting per-team or per-product budgets with alerts). Most organizations practicing FinOps consistently see meaningful savings within the first quarter — often in the 20–40% range on their compute spend.
Is Kubernetes always necessary for a startup?
No. Kubernetes adds operational complexity that early-stage startups rarely need. Managed container services such as AWS ECS, Google Cloud Run, or Azure Container Apps often deliver better value until you reach the scale or architectural complexity that genuinely justifies container orchestration. The right test is whether your team has the operational maturity to run Kubernetes confidently in production — not whether it’s on trend.
What is the difference between an internal hire and an outsourced DevOps partner?
An internal hire offers deep cultural integration but takes months to recruit, weeks to ramp up, and brings experience limited to your stack and previous employers. An outsourced partner brings immediate cross-industry experience and proven patterns across dozens of environments, ideal for accelerating maturity quickly. Many scaleups blend both approaches effectively: a partner builds the foundation and establishes standards, while internal hires sustain and extend it over time.
How long does it take to build a DevOps foundation from scratch?
A functional CI/CD pipeline and basic IaC can be operational within 4–8 weeks for most environments. Full maturity — including DevSecOps automation, a coherent observability stack, and disciplined FinOps practices — typically takes 3–6 months, depending on system complexity, the depth of existing technical debt, and how quickly your internal team can absorb knowledge transfer alongside their product work.
Can DevOps services be delivered on a short-term project basis?
Yes. Many engagements are scoped as defined projects with clear deliverables, particularly for CI/CD pipeline setup, cloud migration, or Kubernetes adoption. Project-based work is well-suited when you have an internal team ready to take ownership afterward and a clearly bounded problem to solve. It’s a low-risk way to validate a partner relationship before committing to a longer-term arrangement.
Sentice is a boutique tech partner that builds custom software solutions for startups and scaleups. We embed senior engineers into your product organization as a real extension of your team — culture-aligned, end-to-end, and committed to your roadmap.