Software Development Challenges: A Practical Guide for Engineering Leaders
Identify the recurring obstacles that slow your roadmap and apply proven mitigations that keep delivery predictable.
- Software development challenges are systemic and compound across technical, process, and human dimensions — treat them as predictable risks, not one-off surprises.
- Vague requirements are the costliest obstacle: measurable acceptance criteria and a clear Definition of Done eliminate most rework cycles.
- Scope creep is best managed with a lightweight change-impact process that forces explicit trade-offs before anything new enters the sprint.
- Testing shifted left — unit and integration tests written alongside code — dramatically reduces end-of-cycle QA crunch and overall lifecycle cost.
- Technical debt compounds like a tax; the boy-scout rule (leave code slightly better each story) outperforms big-bang refactoring projects under real business pressure.
- An embedded, culture-aligned engineering partner shortens the distance between product intent and technical execution, keeping delivery aligned with business goals.
Table of Contents
- Understanding Software Development Challenges and Their Recurring Nature
- Early Warning Signs That Your Project Is Drifting Off Course
- Why Vague Requirements Are the Most Expensive Problem in Software
- Managing Scope Creep Without Halting Business Momentum
- How to Estimate Time and Budget With Greater Accuracy
- Closing the Communication Gap Between Product, Engineering, and Stakeholders
- The Hidden Cost of Skipping Documentation
- Managing Technical Debt as a Strategic Asset, Not a Side Effect
- Why QA Often Explodes Right Before Launch
- Third-Party Integrations and the Obstacles They Introduce
- Performance and Scalability Issues That Only Appear in Production
- Long-Term Risks in Technology Stack Selection
- Comparing Common Software Development Challenges and Their Mitigations
- Monolith vs. Microservices: Choosing the Right Level of Complexity
- Integrating Security Without Slowing Down Releases
- Managing Distributed and Remote Engineering Teams
- Mapping Business Needs to Practical Engineering Support
- A Practical Action Plan for Your Next Project
- Frequently Asked Questions
In today’s fast-moving technology landscape, software development challenges have become a defining factor between scaleups that ship reliably and those that constantly fight fires. Most engineering leaders we work with don’t suffer from a single broken process — they deal with a layered combination of unclear requirements, fragile architecture choices, fragmented communication, and testing that keeps slipping to the end. The result is predictable: timelines stretch, budgets balloon, and quality erodes just when business pressure is highest.
This guide breaks down the recurring obstacles your team is most likely to face, how to detect them early, and the practical moves that keep delivery steady — so your roadmap stays aligned with business goals instead of being held hostage by surprises. At Sentice, we’ve helped startups and scaleups navigate every pattern described here, and the approach we share below reflects what actually works across real product organizations under real pressure.
Understanding Software Development Challenges and Their Recurring Nature
Software development challenges are systemic obstacles that build up across three dimensions — technical, process, and human — and quietly compound until they threaten timeline, budget, and product quality. They’re rarely a single bug or a one-off mistake; they’re the cumulative effect of vague requirements, premature architectural decisions, inconsistent communication between product and engineering, and inadequate investment in testing and documentation.
Treating them as isolated incidents is the most common mistake we see. The teams that move fastest treat these patterns as predictable risks to manage, not surprises to react to. For leaders who want deeper technical insights for growing companies, proactive problem-solving starts by mapping which of these recurring patterns currently dominate your delivery cycle.
Architectural mismatches, accumulated technical debt, fragile integrations, and performance ceilings that only reveal themselves under production load.
Unclear requirements, absent Definition of Done, unmanaged scope changes, and testing treated as an afterthought rather than a continuous discipline.
Misaligned incentives between product and engineering, knowledge siloed in individuals, and communication patterns that surface dependencies too late to act on.
Early Warning Signs That Your Project Is Drifting Off Course
When your team spends more energy on firefighting than on planned milestones, you’re already inside a systemic problem — not approaching one. The earliest signals are quieter than outages: tasks that stay “almost done” for weeks, rework piling up after every code review, a steady spike in regressions following each release, and a growing dependency on a single engineer who “knows how it works.”
Velocity drops slowly, morale dips, and small decisions start requiring senior attention. Catching these signals early lets you intervene with process adjustments rather than emergency rewrites. A useful rule of thumb: if your standups have shifted from “what we’re building” to “what’s broken,” your project obstacles have become structural.
Track three leading indicators every sprint: the ratio of planned to unplanned work, the percentage of stories reopened after “done,” and the time between code merge and production deploy. Movement in any one of these predicts a delivery problem before it becomes a crisis.
Why Vague Requirements Are the Most Expensive Problem in Software
Unclear requirements force teams to build the wrong thing first, then pay again to rebuild it. This “build it twice” pattern is one of the most expensive development problems, and it almost always traces back to missing definitions of success, non-measurable acceptance criteria, and conflicting assumptions among stakeholders.
Drafting Effective Requirements with Definition of Done
A strong Definition of Done makes “complete” objective: code merged, tests passing, documentation updated, and acceptance criteria verified. Without it, “done” becomes negotiable — and negotiable work is the seed of rework. Every team should be able to articulate their DoD in a single paragraph that any new engineer can apply without interpretation.
Aligning Product, Development, and QA via Acceptance Criteria
Acceptance criteria written in measurable, testable language eliminate dual interpretation between product, engineering, and QA. The goal is that three people reading the same ticket reach the same conclusion about success. If they don’t, the ticket isn’t ready to develop.
Moving from Subjective Requests to Measurable Outcomes
“Make it faster” is a wish; “p95 response time under 300ms for the checkout endpoint” is a requirement. Measurable outcomes turn ambiguity into engineering work that can be planned, estimated, and verified against a clear standard — which also protects the team from scope disputes at demo time.
- Success criteria are measurable and unambiguous
- Acceptance criteria written in testable language
- Definition of Done agreed by product, eng, and QA
- Dependencies and external blockers identified
- Edge cases and error states documented
- “Make it feel faster” with no baseline metric
- Acceptance criteria written after development starts
- Single stakeholder defining requirements without QA input
- No explicit non-goals or out-of-scope boundaries
- Requirements updated verbally without ticket revision
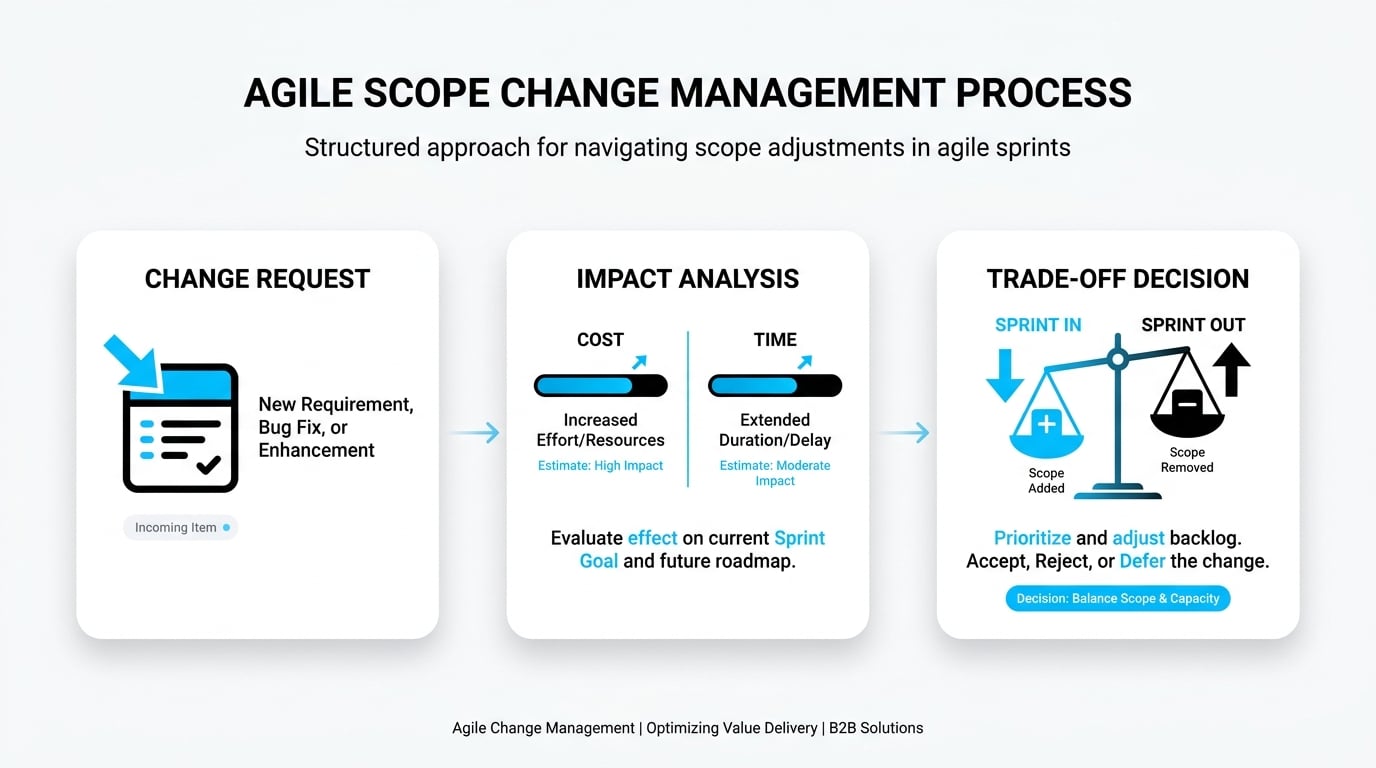
Managing Scope Creep Without Halting Business Momentum

Scope creep isn’t caused by saying “yes” too often — it’s caused by saying “yes” without a mechanism. Healthy teams don’t try to freeze scope; they install a lightweight change process that evaluates impact on cost, time, and risk before anything new enters the sprint. Every addition forces an explicit trade-off: what comes out so this can come in?
Academic research frames feature creep, requirements creep, and scope creep as quantifiable penalties on project outcomes, not soft management problems — see the Ben-Gurion University study on excessive software development practices and penalties. Building this trade-off muscle into your weekly rhythm protects both delivery and stakeholder trust. The change process doesn’t need to be bureaucratic — a shared log and a five-minute impact assessment before any addition enters the backlog is enough for most teams.
For every item added to an active sprint, make the displacement explicit: which existing story is deprioritized or deferred? This single discipline prevents the gradual inflation of iteration scope that erodes velocity and predictability over time.
How to Estimate Time and Budget With Greater Accuracy
Reliable estimation rests on three pillars: granular work breakdown, explicit uncertainty, and historical velocity — never gut feel. Single-date estimates create the illusion of certainty and almost always disappoint. The goal isn’t a perfect forecast; it’s a forecast honest enough to drive good decisions.
The Dangers of Fixed-Date Illusions
A single date hides risk. It tells stakeholders “this will happen on Tuesday” when reality is a probability distribution. When the date slips, trust erodes faster than the timeline did. Range-based estimates — “we’re 80% confident this ships between Week 6 and Week 9” — communicate the same information more honestly and invite earlier conversation about risk.
Using Best, Most Likely, and Worst-Case Scenarios
Three-point estimation (optimistic, most likely, pessimistic) forces the team to identify what would push the project toward the worst case — turning estimation into a risk-discovery exercise that surfaces unknowns before they become surprises. The spread between optimistic and pessimistic is itself useful data: wide spread means high uncertainty that deserves investigation.
Accounting for Integration, Security, and Data Risks
Integration unknowns, security review cycles, and messy production data are the three estimation killers that most teams consistently undercount. Bake explicit buffers for each into your plan rather than discovering them mid-sprint. A simple rule: if the story touches an external API, a security boundary, or a data migration, add at least 30% to your estimate before presenting it.
Closing the Communication Gap Between Product, Engineering, and Stakeholders
Most communication breakdowns aren’t about tools — they’re about misaligned KPIs. Business teams optimize for feature velocity and revenue impact; engineering optimizes for stability, maintainability, and long-term cost. When neither side translates its priorities into the other’s language, you get decisions made without context and dependencies discovered too late.
The fix is structural: shared dashboards that show both delivery progress and technical risk, regular trade-off conversations, and a culture where surfacing concerns early is rewarded rather than penalized. Sentice teams work as an embedded extension of your in-house staff, which naturally shortens the distance between product intent and technical execution — decisions get made with full context, not in silos. This partnership model means your roadmap and your architecture evolve together, aligned from the start.
DORA research consistently shows that high-performing engineering organizations share one cultural marker above all others: psychological safety to raise risks without fear of blame. Teams where engineers surface problems early have significantly higher deployment frequency and lower change failure rates than teams where problems are concealed until they become crises.
The Hidden Cost of Skipping Documentation
When documentation is treated as optional, knowledge stays trapped in individual heads — and the system slowly becomes brittle. Onboarding new engineers takes weeks instead of days, the same incidents recur because root causes were never written down, and any senior departure creates an immediate capability gap that can set a team back months.
Good documentation isn’t about producing thick manuals; it’s about capturing the decisions that future engineers will need to understand: why an architecture was chosen, which trade-offs were accepted, and what the system intentionally does not do. Lightweight architecture decision records (ADRs), runbooks for incidents, and clear API contracts deliver outsized returns relative to the time they cost. In our experience, teams that maintain even minimal structured documentation reduce onboarding time by 40–60% and cut incident recurrence rates significantly — a straightforward return on a modest investment.
Managing Technical Debt as a Strategic Asset, Not a Side Effect
Technical debt is a future tax on present shortcuts — and like any tax, it compounds. Left unmanaged, it transforms a codebase from an asset that accelerates delivery into a liability that resists every change. The distinction matters: debt isn’t inherently bad. A deliberate shortcut to meet a launch deadline, logged and scheduled for remediation, is a sound business decision. Undocumented debt that accumulates invisibly is the real threat.
Distinguishing Between Technical Debt, Bugs, and Bad Architecture
Bugs are incorrect behavior. Technical debt is intentionally suboptimal code that worked at the time and was understood to require future improvement. Bad architecture is a structural mismatch between system design and current needs — often the product of requirements that changed after the design was frozen. Each requires a different remediation strategy: bugs get fixed in the next sprint, debt gets scheduled and paid down continuously, and architectural mismatches need a deliberate migration plan.
Measuring Debt Without Relying on Gut Feeling
Track concrete signals: build and CI duration, regression rates per release, time-to-onboard new engineers, and the percentage of stories blocked by “we need to refactor X first.” These metrics turn debt from anecdote into data that can be presented to business stakeholders and prioritized against feature work with equal rigor.
The Continuous Improvement Strategy
The most sustainable approach is the boy-scout rule: every change leaves the code slightly better than it found it. Big-bang refactoring projects rarely survive contact with business priorities — they get deprioritized when a deadline appears. Small, continuous improvements always do, because they’re embedded in normal delivery rather than competing with it.
Why QA Often Explodes Right Before Launch
When testing is treated as the final checkpoint rather than an integrated part of the SDLC, systemic issues surface only when they’re most expensive to fix. The pattern is consistent: testing compressed into the last week before release, issues discovered that require architectural changes, timeline slips, and stakeholder trust eroding at exactly the wrong moment. Research on Verification, Validation, and Testing economics — see the Tel Aviv University methodology for modeling VVT risks and costs — shows that testing strategy directly drives lifecycle cost, not just release-day quality.
Implementing the Testing Pyramid
Many fast unit tests at the base, fewer integration tests in the middle, and a small set of end-to-end tests at the top. This shape gives you fast feedback during development — failures caught in seconds, not hours — and confidence at release without a brittle, slow test suite that the team learns to distrust and skip.
Automating vs. Manual Testing Strategically
Automate the repetitive, deterministic, and high-frequency: regression suites, API contract tests, performance benchmarks. Keep humans for exploratory testing, UX judgment, and edge cases that change too often to be worth scripting. Misapplying automation — trying to automate everything including volatile UI flows — wastes more time maintaining tests than it saves.
Definition of Ready and Done for QA
Stories shouldn’t enter development without clear acceptance criteria, and they shouldn’t leave it without verified tests mapped to those criteria. This single discipline prevents the end-of-sprint QA crunch that creates the launch-week explosion — and it makes QA a continuous flow rather than a bottleneck gate.
Third-Party Integrations and the Obstacles They Introduce
Every external dependency adds uncertainty: API versions change, rate limits tighten, response formats drift, and outages happen on someone else’s schedule. The defensive pattern is to wrap every third-party integration in an abstraction layer your team controls, so a vendor change becomes a localized refactor instead of a system-wide emergency.
Add timeouts, retries with exponential backoff, circuit breakers, and clear structured logging at every integration boundary. Then test the failure modes — not just the happy path — because integration failures in production are usually how teams discover what they assumed. Mocking external services in tests and running periodic contract-verification checks catches drift before it reaches users.
For each third-party integration, document: the maximum acceptable latency, the retry strategy, the circuit-breaker threshold, and the fallback behavior when the vendor is unavailable. This four-point spec takes fifteen minutes to write and can save hours of production debugging when something changes without notice.
Performance and Scalability Issues That Only Appear in Production
Performance problems hide in development environments where data volumes are small, traffic is predictable, and usage patterns are clean. Production reveals the truth: real users behave unexpectedly, datasets grow non-linearly, and infrastructure costs climb in ways the architecture never anticipated. The database query that runs in 20ms against 10,000 rows runs in 8 seconds against 10 million — and nobody tested it at scale.
The defense is observability built in from day one — structured logs, distributed tracing, and meaningful metrics on the paths that matter to the business: checkout flows, search, authentication, data exports. When you can see what the system is actually doing, scaling becomes an engineering problem you can solve with data, not a mystery you have to investigate under pressure while users are affected.
Long-Term Risks in Technology Stack Selection
Stack choices outlive the people who make them. A technology that feels productive for the first six months can become a hiring problem, a maintenance burden, or a performance ceiling three years later. The engineer who championed the choice may have left, the ecosystem may have stagnated, and the team is now committed to something that no longer serves the product.
Evaluate stacks against five criteria: fit to the actual problem domain, ecosystem maturity and community health, observability and debugging tooling, talent availability in your hiring market, and the realistic cost of changing direction later. Trendy choices made under deadline pressure — adopting a new framework because it’s generating conference buzz — are the ones most likely to be regretted when the hype cycle moves on and the maintenance burden remains.
Comparing Common Software Development Challenges and Their Mitigations

| Challenge | Early Signal | Primary Mitigation |
|---|---|---|
| Vague requirements | Recurring rework after demos | Measurable acceptance criteria + Definition of Done |
| Scope creep | “Just one more thing” mid-sprint | Formal change-impact process with explicit trade-offs |
| Technical debt | Slower releases, more regressions | Continuous small improvements (boy-scout rule) |
| QA bottlenecks | Testing pushed to release week | Shift-left testing pyramid integrated into SDLC |
| Integration fragility | Breakages on vendor updates | Abstraction layer, circuit breakers, and failure-mode tests |
| Performance surprises | Slow queries under real load | Observability and load testing from day one |
| Security gaps | Issues found in audit, not design | Secure SDLC — threat modeling and scanning in CI |
Monolith vs. Microservices: Choosing the Right Level of Complexity
Microservices are powerful — and frequently adopted too early. The operational overhead of distributed systems (service discovery, observability, deployment orchestration, data consistency) is often higher than the benefits for teams that haven’t yet hit the scale that justifies it. The conversation should start with “what problem are we solving?” not “what architecture is modern?”
When a Monolith Is the Right Business Decision
For early-stage products, small teams, and unclear domain boundaries, a well-structured monolith ships faster, debugs easier, and refactors more cheaply than a distributed architecture. The domain boundaries you’d need to draw service lines around often only become clear after you’ve shipped the first version and seen how users actually use the product.
The Operational Overhead of Microservices
Each service adds deployment complexity, network failure modes, distributed tracing requirements, and data consistency challenges. Without mature DevOps practices — container orchestration, service mesh, centralized logging, distributed tracing — microservices become more painful than the problem they were meant to solve. The operational cost is real and ongoing, not a one-time setup expense.
Transitioning Architectures Safely
The strangler-fig pattern — extracting services gradually from a monolith based on real scaling needs, not anticipated ones — almost always beats a big-bang rewrite. Sentice provides end-to-end software development support for teams making these architectural transitions, ensuring your building blocks grow with your company instead of against it, with each step validated against actual load and business requirements.
Integrating Security Without Slowing Down Releases

Security treated as a final-stage gate becomes a release blocker; security integrated into the SDLC becomes invisible. Modern Secure SDLC practice means dependency scanning in CI, automated checks for secrets in code, threat modeling during design, and clear ownership for vulnerability response — none of which require slowing down the deployment pipeline.
Open-source components — which power most modern systems — deserve particular attention, since unmaintained dependencies are a common source of exposure that automated tooling can catch early. Israel’s Privacy Protection Authority published detailed guidance on this in its principles for managing information security risks in open-source code. Embedded security review during design — not after — is what keeps releases fast and safe, and what prevents the audit-finding surprises that derail launch timelines.
Managing Distributed and Remote Engineering Teams
Distributed teams trade co-location for flexibility, but the trade is only worthwhile when communication discipline is high. Hand-offs across time zones can either compress delivery cycles or fragment them, depending on documentation rigor and asynchronous communication norms. A team that documents decisions, writes clear pull-request descriptions, and records context in tickets can move faster across time zones than a co-located team that relies on hallway conversation.
Effective distributed teams over-invest in written context: decisions captured in writing, clear ownership per component, and meeting cadences designed for time-zone fairness rather than one team’s convenience. Culture-aligned partners who already operate this way reduce the friction of scaling beyond your local market. The discipline required for distributed work also happens to make co-located teams more effective — it’s a forcing function for clarity that benefits everyone.
Mapping Business Needs to Practical Engineering Support
| Business Need | How an Embedded Partnership Helps |
|---|---|
| Scale capacity quickly without long hiring cycles | Senior engineers integrated into your existing team within weeks, not months |
| Predictable delivery on critical roadmap items | Dedicated, aligned squads operating in your sprint cadence with shared accountability |
| Reduce technical debt while shipping features | Continuous-improvement practices built into daily delivery — no separate “debt sprint” required |
| Keep security and quality high under pressure | Secure SDLC and testing pyramid implemented from day one as standard practice |
| Adapt to changing requirements without chaos | Lightweight change-management process tied to impact analysis and explicit trade-offs |
A Practical Action Plan for Your Next Project
Start with a focused requirements workshop that produces measurable acceptance criteria, not aspirational goals. Define a real MVP — the smallest version that delivers value and validates your assumptions, not the minimum you can get away with shipping. Establish quality standards from day one: CI/CD pipeline, the testing pyramid, structured observability, and a lightweight change-management process that enforces explicit trade-offs.
Run retrospectives that produce decisions, not just discussions — every retro should close with at least one concrete change to how the team operates. None of this requires heavy process; it requires consistency. Teams that install these basics and protect them under pressure consistently outperform teams that try to add them later, when problems are already visible and the cost of correction is highest. Start small, grow fast — and build the habits before you need to scale them.
Pick the one challenge from this guide that is most visibly slowing your current delivery. Write down three concrete signals that confirm it’s active in your team. Then identify the single smallest process change — one meeting format, one template, one definition — that would make that signal visible earlier. That’s your first action. Everything else follows from there.
Frequently Asked Questions
What is the biggest software development challenge today?
For most scaleups, it’s the gap between business velocity expectations and the engineering reality of building maintainable systems. The technical work is rarely the bottleneck — alignment, requirements clarity, and disciplined trade-off management are. Teams that close this gap through shared context and honest communication consistently outperform those that try to accelerate delivery without addressing the underlying alignment deficit.
Why do software projects go over budget?
Almost always because of underestimated scope, unmanaged change requests, and discovery work disguised as delivery work. Work that looked straightforward in planning reveals complexity during implementation — integration unknowns, data quality issues, security requirements that weren’t scoped. Range-based estimation and a formal change process address most of the root causes by surfacing uncertainty before it becomes cost overrun.
How do you know if requirements are clear enough to start development?
Apply the three-person test: if three people from product, engineering, and QA can read the requirement independently and describe the same successful outcome without consulting each other, it’s clear enough to build. If they reach different conclusions, the ambiguity they’ve surfaced will resurface as rework during development — better to resolve it in a thirty-minute conversation now than in a two-day revision cycle later.
How much time should be allocated to QA in a software project?
Rather than a fixed percentage, integrate testing throughout development. Teams that shift testing left — unit and integration tests written alongside code, acceptance criteria verified before a story closes — typically reduce total QA time while improving quality. The question isn’t “how much QA time?” but “at what point in the SDLC does testing happen?” Earlier is almost always faster and cheaper overall.
How do you reduce technical debt under feature pressure?
Use the boy-scout rule: every story leaves the touched code slightly better than it found it. This compounds over months without requiring a dedicated “refactoring sprint” that business stakeholders will resist when a deadline appears. Pair it with concrete debt metrics — CI duration, regression rates, onboarding time — so the conversation with stakeholders is grounded in data rather than engineering preference.
Are microservices right for every product?
No. Microservices suit teams and products that have already hit scale limits a well-structured monolith couldn’t solve, and that have the DevOps maturity to operate distributed systems reliably. Most early-stage products ship faster, debug easier, and refactor more cheaply on a monolith. The strangler-fig pattern — extracting services gradually based on real scaling evidence — is almost always safer than a speculative distributed architecture designed before the product is proven.
How do you integrate security without delaying releases?
Build it into the SDLC as a continuous practice rather than a final gate. Automated dependency scanning and secrets detection run in CI without blocking deploys unless critical findings are present. Threat modeling happens during design, so security requirements are known before implementation begins. Clear vulnerability ownership ensures findings are triaged and resolved within defined SLAs. Security as a gate creates delays; security as a continuous practice becomes part of normal delivery rhythm.
When should a scaleup consider an embedded engineering partner?
The right moment is typically when delivery velocity has stalled despite growing headcount, when a critical roadmap initiative needs senior capacity faster than internal hiring can provide, or when specific expertise — architecture, security, performance — is needed for a defined period. An embedded boutique partner integrates as a genuine extension of your team: operating in your sprint cadence, aligned to your culture, and accountable to your roadmap — rather than delivering a fixed scope and disengaging.
Sentice is a boutique tech partner that builds custom software solutions for startups and scaleups. We embed senior engineers into your product organization as a real extension of your team — culture-aligned, end-to-end, and committed to your roadmap.